Two datasets have been used for this dataset- the FAOSTAT cattle and the FAOSTAT chicken ones. They are time-series datasets with information about the amount of eggs and chicken yielded or produced. The information is present for several countries.
Generated by summarytools 1.0.1 (R version 4.2.1) 2022-08-25
Tidy Data (as needed)
The data is already tidy in both the datasets. In the item column, there was unnecessary text so I removed that.
dairy<-dairy%>%mutate(Item=str_remove(Item,", whole fresh cow"))egg<-egg%>%mutate(Item=str_remove(Item,", hen, in shell"))
Join Data
At first, I joined the datasets by doing an inner join and using the common column as year. However, both the datasets, have the same column names and information and using inner join created more columns, essentially a duplicate, with the same information.
I realised that I wanted to add the rows from the FAOSTAT chicken dataset to the existing FAOSTAT cattle dataset. Therefore, I used rbind() to join the two datasets.
#full_join()dairy_egg<-dairy %>%inner_join(egg, by ="Year")head(dairy_egg)
Generated by summarytools 1.0.1 (R version 4.2.1) 2022-08-25
Analysis
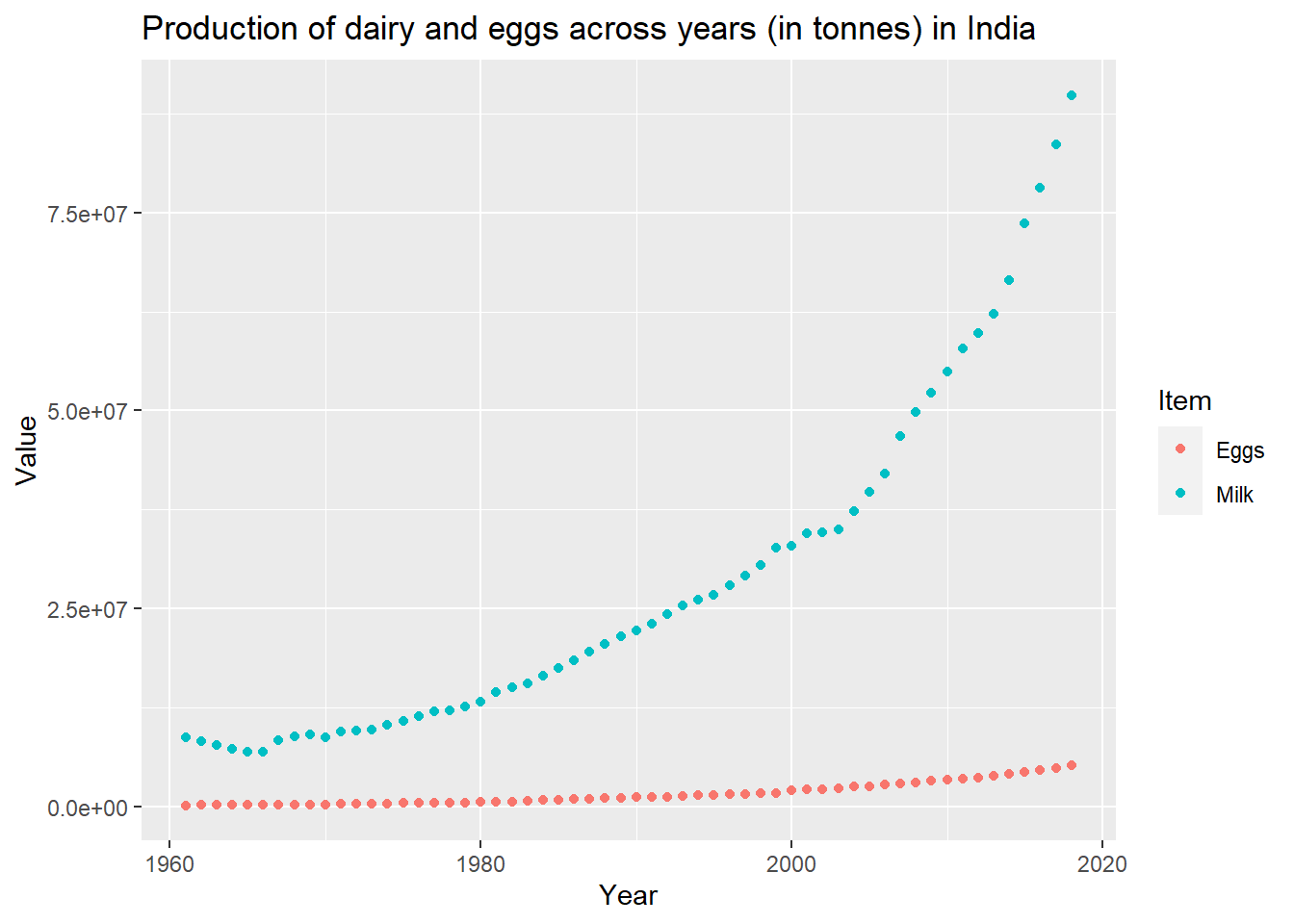
Before analysis, I filtered the dataset to only have the production values since these were measured by the same quantity(tonnes) for milk and eggs. Hence they could be compared. Moreover, I filtered the data to have values from India.
In the scatterplot below, it is evident that the milk production has increased at a rapid rate from 1961 to 2018. This could correspond to the increase in population and popular consumption of milk. However, the eggs production has not had such a rapid increase in the same time period. This may be attributed to the fact that several Indians follow a vegetarian diet which does not include the consumption of eggs.
new_dairy_egg_sub<-new_dairy_egg%>%filter(Element=="Production")%>%filter(Area=="India")#year,item,valueggplot(new_dairy_egg_sub, aes(x=Year,y=Value, color=Item)) +geom_point() +labs(title ="Production of dairy and eggs across years (in tonnes) in India")
Source Code
---title: "Challenge 8 "author: "Mekhala Kumar"description: "Joining Data"date: "08/25/2022"format: html: toc: true code-copy: true code-tools: truecategories: - challenge_8 - faostat---```{r}#| label: setup#| warning: false#| message: falselibrary(tidyverse)library(ggplot2)library(readr)knitr::opts_chunk$set(echo =TRUE, warning=FALSE, message=FALSE)```## Description of the dataTwo datasets have been used for this dataset- the FAOSTAT cattle and the FAOSTAT chicken ones. They are time-series datasets with information about the amount of eggs and chicken yielded or produced. The information is present for several countries.```{r}dairy <-read_csv("_data/FAOSTAT_cattle_dairy.csv")egg <-read_csv("_data/FAOSTAT_egg_chicken.csv")dim(dairy)dim(egg)print(summarytools::dfSummary(dairy,varnumbers =FALSE,plain.ascii =FALSE, style ="grid", graph.magnif =0.70, valid.col =FALSE),method ='render',table.classes ='table-condensed')print(summarytools::dfSummary(egg,varnumbers =FALSE,plain.ascii =FALSE, style ="grid", graph.magnif =0.70, valid.col =FALSE),method ='render',table.classes ='table-condensed')```## Tidy Data (as needed)The data is already tidy in both the datasets. In the item column, there was unnecessary text so I removed that.```{r}dairy<-dairy%>%mutate(Item=str_remove(Item,", whole fresh cow"))egg<-egg%>%mutate(Item=str_remove(Item,", hen, in shell"))```## Join DataAt first, I joined the datasets by doing an inner join and using the common column as year. However, both the datasets, have the same column names and information and using inner join created more columns, essentially a duplicate, with the same information.\I realised that I wanted to add the rows from the FAOSTAT chicken dataset to the existing FAOSTAT cattle dataset. Therefore, I used rbind() to join the two datasets.```{r}#full_join()dairy_egg<-dairy %>%inner_join(egg, by ="Year")head(dairy_egg)tail(dairy_egg)dim(dairy_egg)new_dairy_egg<-rbind(dairy,egg)head(new_dairy_egg)tail(new_dairy_egg)dim(new_dairy_egg)print(summarytools::dfSummary(new_dairy_egg,varnumbers =FALSE,plain.ascii =FALSE, style ="grid", graph.magnif =0.70, valid.col =FALSE),method ='render',table.classes ='table-condensed')```## AnalysisBefore analysis, I filtered the dataset to only have the production values since these were measured by the same quantity(tonnes) for milk and eggs. Hence they could be compared. Moreover, I filtered the data to have values from India.\In the scatterplot below, it is evident that the milk production has increased at a rapid rate from 1961 to 2018. This could correspond to the increase in population and popular consumption of milk. However, the eggs production has not had such a rapid increase in the same time period. This may be attributed to the fact that several Indians follow a vegetarian diet which does not include the consumption of eggs.```{r}new_dairy_egg_sub<-new_dairy_egg%>%filter(Element=="Production")%>%filter(Area=="India")#year,item,valueggplot(new_dairy_egg_sub, aes(x=Year,y=Value, color=Item)) +geom_point() +labs(title ="Production of dairy and eggs across years (in tonnes) in India")```